Approach
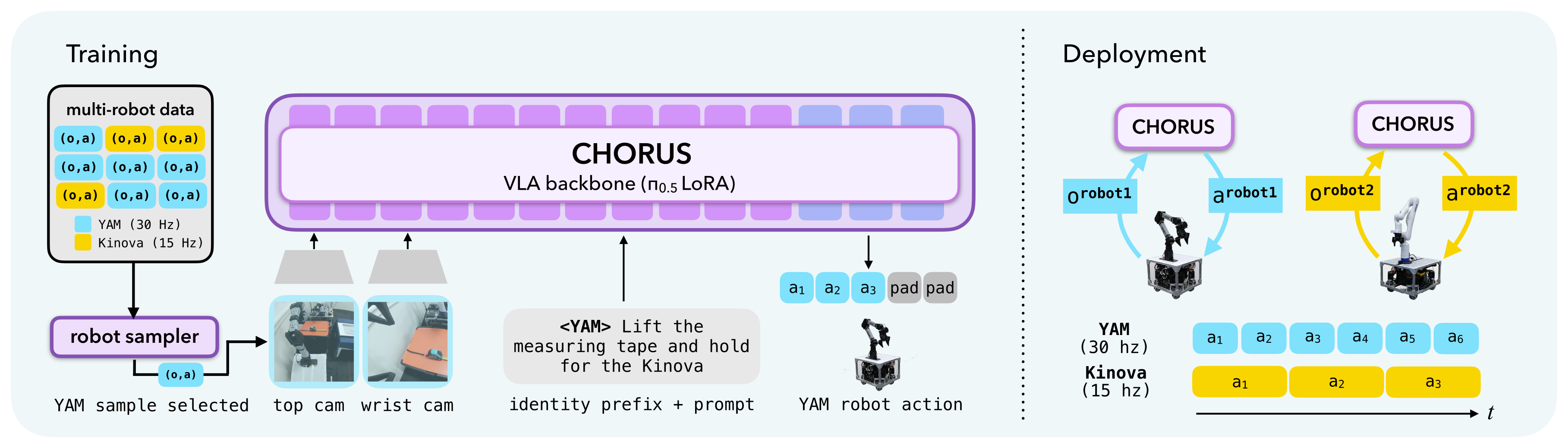
CHORUS fine-tunes a single VLA backbone on multi-robot data and deploys an independent copy on each robot.
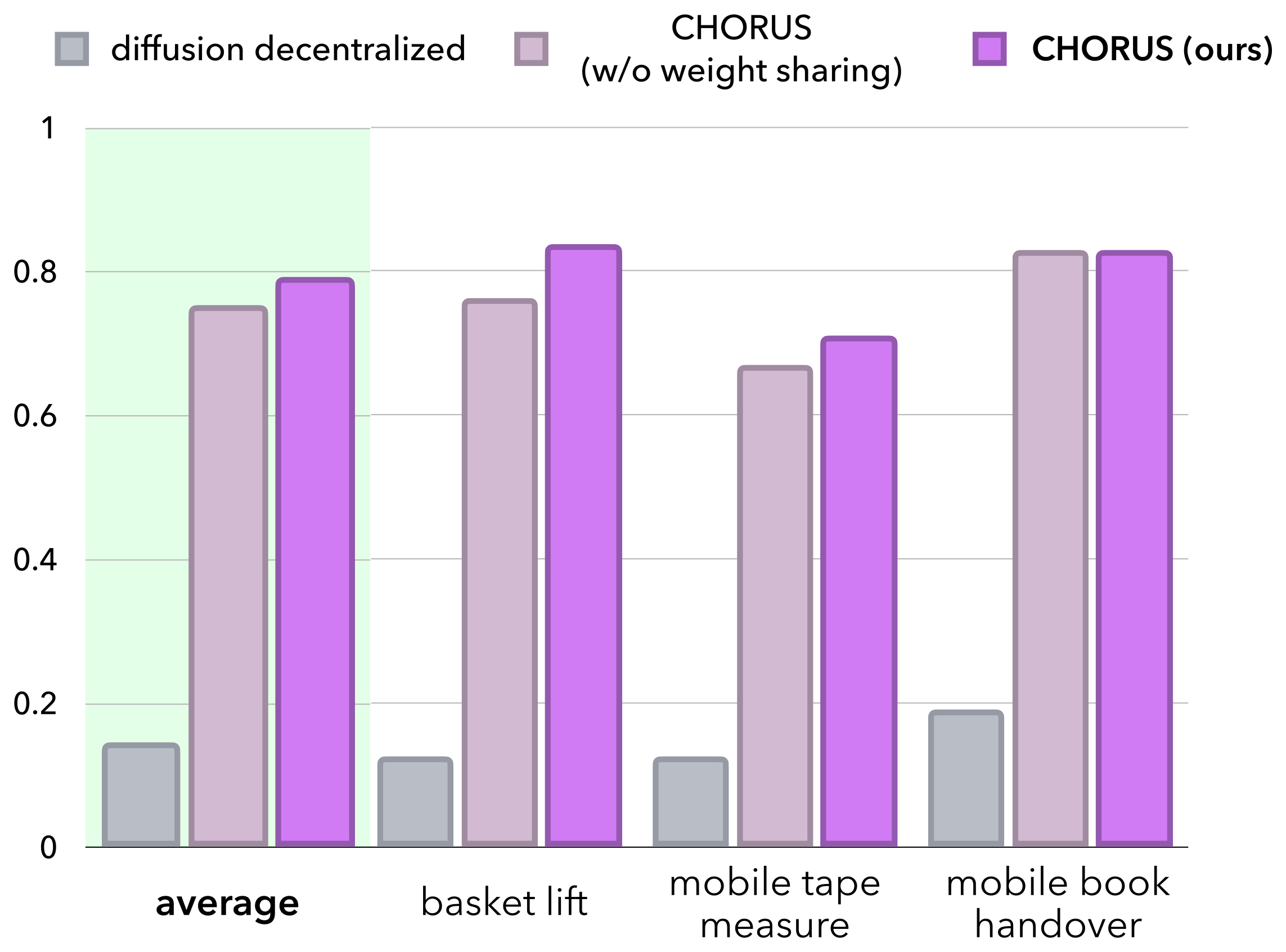
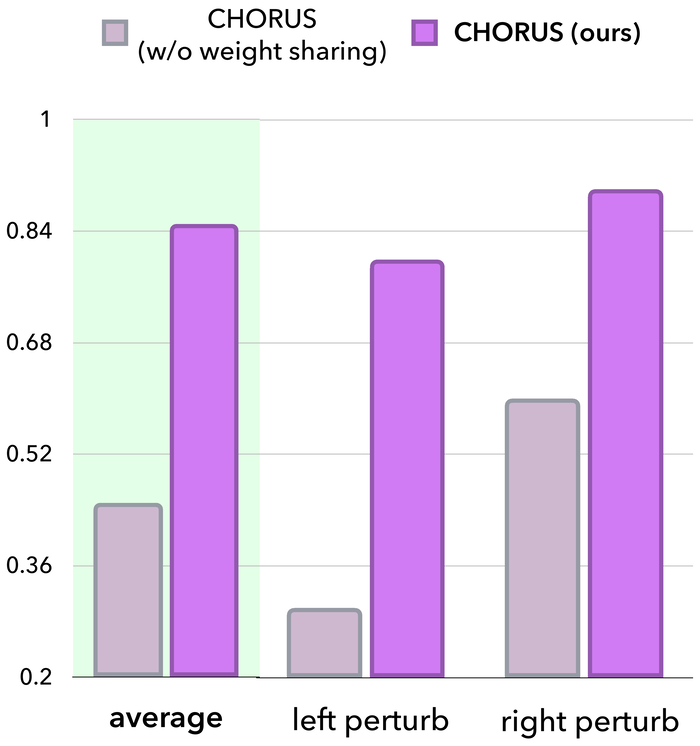
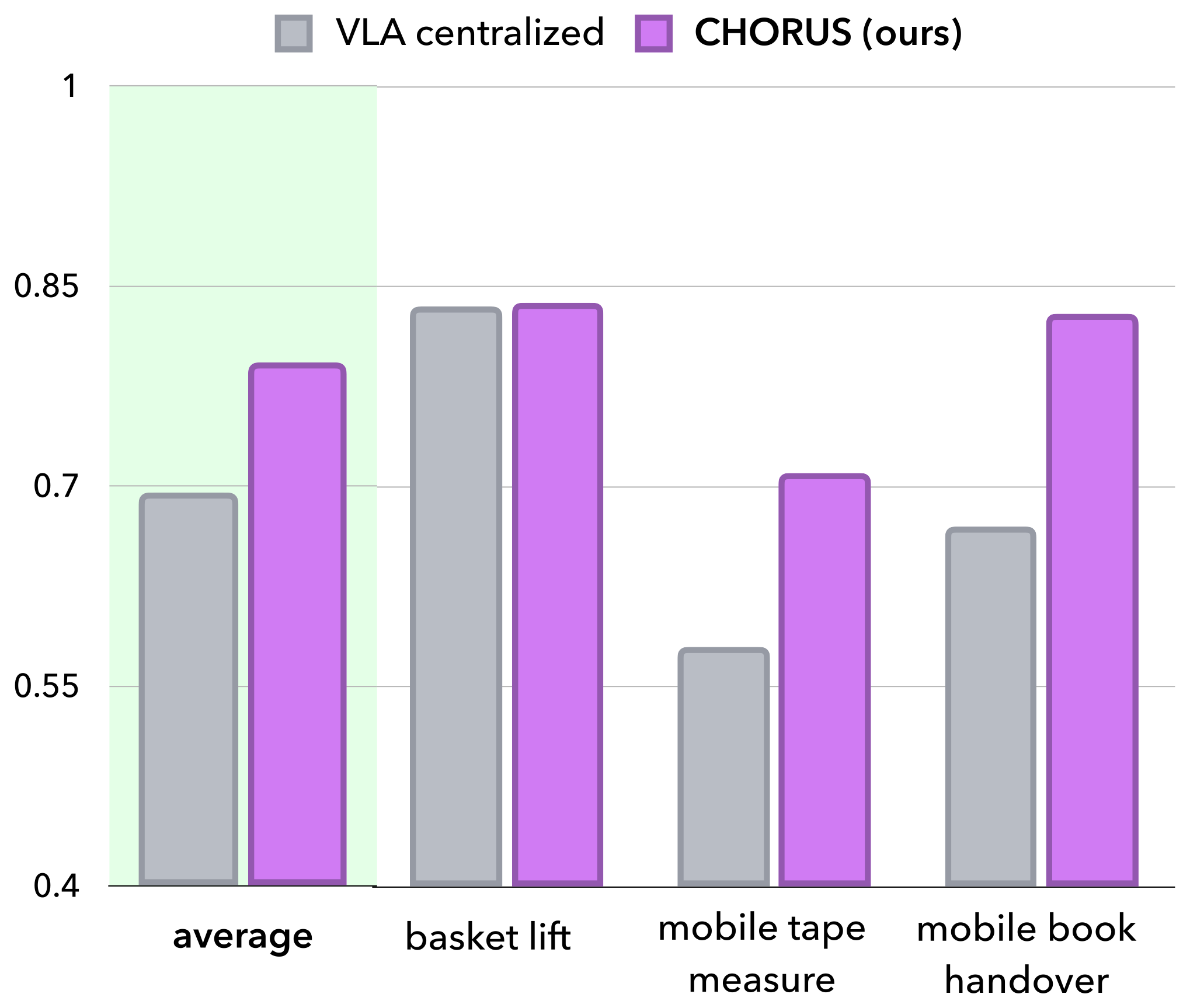
Our key insight is that strong visuomotor priors may be sufficient to enable decentralized, multi-embodiment collaboration without alignment or communication at inference. To this end, CHORUS finetunes a single pretrained VLA backbone (π0.5) on multi-robot demonstrations. A robot sampler draws single-robot tuples (observation, action) from the multi-robot dataset, and the shared policy is conditioned on a robot-identifying prompt prepended at every timestep. It predicts a padded, 32-dimensional action, so one set of weights can drive embodiments with different action spaces and control rates.
At deployment, the shared weights run independently on each robot, conditioned only on that robot's own cameras and identity prompt, yielding fully decentralized execution. No cameras, proprioceptive states, or communication channels are shared among robots, making CHORUS more deployable than centralized alternatives and cheaper to train than per-robot decentralized policies. Because each robot acts on its own observations, CHORUS also supports asynchronous execution and keeps the context window constant as the team size grows.